
What is the latent space and what is it used for?
Latent space is an abstract multidimensional space containing characteristic values that cannot be directly interpreted, but which are encoded in a meaningful internal representation.
In the case of neural networks, trained models produce a vector space, or a compressed representation of the information. This compressed version of the data distribution is defined as latent space.
A particularly interesting case is the data representation constructed in an encoder/decoder model,
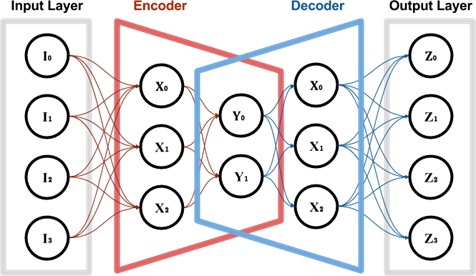
where it’s easy to see how the input data, for instance, is represented in a different n-dimensional space.
It’s worth noting that the concept of simplifying or representing information in a system that’s different or transformed from reality is also part of our nature as human beings. It’s no coincidence that the brain tends to simplify original information by breaking it down into easily usable information through a sampling/quantization process. From everyday experience, it’s well-known that humans generally can’t memorize all the information they receive; consider, for example, the images we perceive daily, of which we can only retain and process parts.
Similarly to us humans, who understand a wide range of topics and events through simplification processes and representation of acquired information, the latent space aims to provide a computer with a simplified and structured understanding of information through a quantitative spatial representation/modeling.
It’s crucial to understand the importance of observing events in latent space, as significant differences in the observed space/events could be due to small variations in latent space. Given this characteristic, using a latent space as a representation of a neural model’s knowledge is essential and useful for improving performance as the system might work only on primary features, effectively observing a compressed space (for a deeper understanding, consider a study on PCA).
To better grasp the concept, let’s analyze some examples:
Embedding space (in the NLP context): Word embedding consists of vectors representing individual words in latent space where semantically similar words are represented by vectors whose distance is minimal or that lie close to each other. The semantic distance is calculated using cosine or Euclidean distance methods; hence unrelated words are distant from each other. For a visual representation of space, it’s fascinating to examine the tensorflow projector that offers a good idea of the latent space concept by visualizing the embedding space in three dimensions, assuming you’ve reduced the n-dimensional encoding of a word to the Principal Components that allow you to represent the individual data in a three-dimensional space.
Image feature space: In image classification using CNNs, it’s possible to extract information representing them through reduced or transformed features; for more details, perhaps it would be interesting to reread this article.
Methods of topic modeling such as LDA, PLSA use statistical approaches to obtain a reference latent space by observing a set of documents and word distribution.
VAEs and GANs aim to achieve a latent space that closely approximates the real data space observed, to construct similar or analogous versions of reference images.
In all the previous examples, the goal is to find a way to represent data in an observation/latent space that is relatively simpler than the real one, with the aim of approximating the real latent space of the observed data.

I am passionate about technology and the many nuances of the IT world. Since my early university years, I have participated in significant Internet-related projects. Over the years, I have been involved in the startup, development, and management of several companies. In the early stages of my career, I worked as a consultant in the Italian IT sector, actively participating in national and international projects for companies such as Ericsson, Telecom, Tin.it, Accenture, Tiscali, and CNR. Since 2010, I have been involved in startups through one of my companies, Techintouch S.r.l. Thanks to the collaboration with Digital Magics SpA, of which I am a partner in Campania, I support and accelerate local businesses.
Currently, I hold the positions of:
CTO at MareGroup
CTO at Innoida
Co-CEO at Techintouch s.r.l.
Board member at StepFund GP SA
A manager and entrepreneur since 2000, I have been:
CEO and founder of Eclettica S.r.l., a company specializing in software development and System Integration
Partner for Campania at Digital Magics S.p.A.
CTO and co-founder of Nexsoft S.p.A, a company specializing in IT service consulting and System Integration solution development
CTO of ITsys S.r.l., a company specializing in IT system management, where I actively participated in the startup phase.
I have always been a dreamer, curious about new things, and in search of “new worlds to explore.”

Comments