
La sfida tra CNN e Vision Transformers nella rivoluzione della visione artificiale
In questo post vorrei lasciarvi qualche considerazione su due architetture: le Reti Convoluzionali (CNN) e i Transformer Visivi (ViT). Questi potentissimi modelli di deep learning hanno profondamente trasformato l’ambito della visione artificiale. Ma come funzionano realmente? E quali distinzioni esistono tra loro?
Partiamo dal discutere le Reti Convoluzionali (CNN).
Questi modelli si caratterizzano per una struttura a strati multiforme, includendo strati di convoluzione, pooling, completamente connessi e di normalizzazione. Gli strati di convoluzione sono equipaggiati con filtri che perlustrano l’immagine per segmenti ridotti alla volta, il che permette alla rete di focalizzarsi su dettagli molto specifici e locali. L’architettura, include, inoltre strati di pooling, che agiscono come riduttori di dimensione, preservando le informazioni più rilevanti dell’output della convoluzione e rendendo la rete resiliente alle piccole variazioni e distorsioni nell’immagine, infatti un aspetto interessante delle CNN è la loro invarianza alla traslazione: esse sono capaci di riconoscere un oggetto indipendentemente dalla sua posizione nell’immagine.

In contrasto con le CNN, i Transformer Visivi (ViT) adottano un approccio differente. Essi suddividono l’immagine in numerose patch, cioè piccole sezioni quadrate, per poi elaborarle simultaneamente. Questa strategia, porta alla perdita del contesto spaziale dell’immagine, vale a dire la posizione relativa di ciascuna patch all’interno dell’immagine stessa. Per contrapporsi a questa mancanza, i ViT inseriscono esplicitamente un’informazione di posizione a ciascuna patch. Ciò implica che ogni patch viene marcata con la sua posizione originale nell’immagine, per preservare il contesto spaziale durante l’elaborazione.
Il cuore pulsante dei ViT è il modulo del trasformatore, che sfrutta un meccanismo chiamato “attenzione” per determinare il peso relativo di ciascuna patch, il quale permette di valutare le relazioni tra tutte le patch dell’immagine, considerando sia i dettagli locali sia il contesto globale dell’immagine.
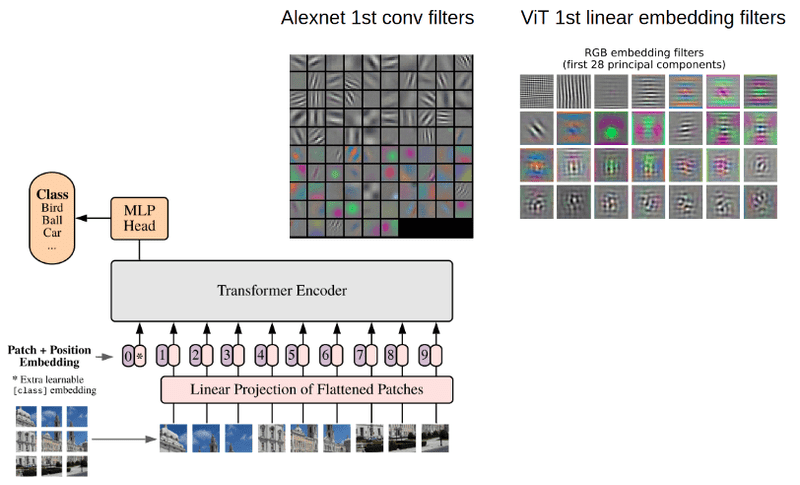
E allora, cosa distingue queste due architetture? La prima differenza riguarda il campo ricettivo: le CNN guardano solo una piccola porzione dell’immagine alla volta (campo ricettivo locale), mentre le ViT considerano l’intera immagine (campo ricettivo globale), inoltre, mentre le CNN automaticamente incorporano le informazioni sulla posizione attraverso le loro operazioni di convoluzione e pooling, le ViT devono esplicitamente aggiungere queste informazioni.
Dal punto di vista computazionale, le CNN tendono ad essere più efficienti su immagini di grandi dimensioni, poiché riducono progressivamente la dimensione dell’immagine attraverso il pooling. Al contrario, le ViT possono essere computazionalmente onerose su immagini di grandi dimensioni, poiché calcolano l’attenzione tra tutte le patch. Infine, le ViT solitamente richiedono set di dati di addestramento più grandi rispetto alle CNN per ottenere buone prestazioni, a causa del loro campo ricettivo globale.
Nonostante queste differenze, sia le CNN che i ViT rappresentano strumenti preziosi nella toolbox di qualsiasi ricercatore o ingegnere in AI.

Sono amante della tecnologia e delle tante sfumature del mondo IT, ho partecipato, sin dai primi anni di università ad importanti progetti in ambito Internet proseguendo, negli anni, allo startup, sviluppo e direzione di diverse aziende; Nei primi anni di carriera ho lavorato come consulente nel mondo dell’IT italiano, partecipando attivamente a progetti nazionali ed internazionali per realtà quali Ericsson, Telecom, Tin.it, Accenture, Tiscali, CNR. Dal 2010 mi occupo di startup mediante una delle mie società techintouch S.r.l che grazie alla collaborazione con la Digital Magics SpA, di cui sono Partner la Campania, mi occupo di supportare ed accelerare aziende del territorio .
Attualmente ricopro le cariche di :
– CTO MareGroup
– CTO Innoida
– Co-CEO in Techintouch s.r.l.
– Board member in StepFund GP SA
Manager ed imprenditore dal 2000 sono stato,
CEO e founder di Eclettica S.r.l. , Società specializzata in sviluppo software e System Integration
Partner per la Campania di Digital Magics S.p.A.
CTO e co-founder di Nexsoft S.p.A, società specializzata nella Consulenza di Servizi in ambito Informatico e sviluppo di soluzioni di System Integration, CTO della ITsys S.r.l. Società specializzata nella gestione di sistemi IT per la quale ho partecipato attivamente alla fase di startup.
Sognatore da sempre, curioso di novità ed alla ricerca di “nuovi mondi da esplorare“.
